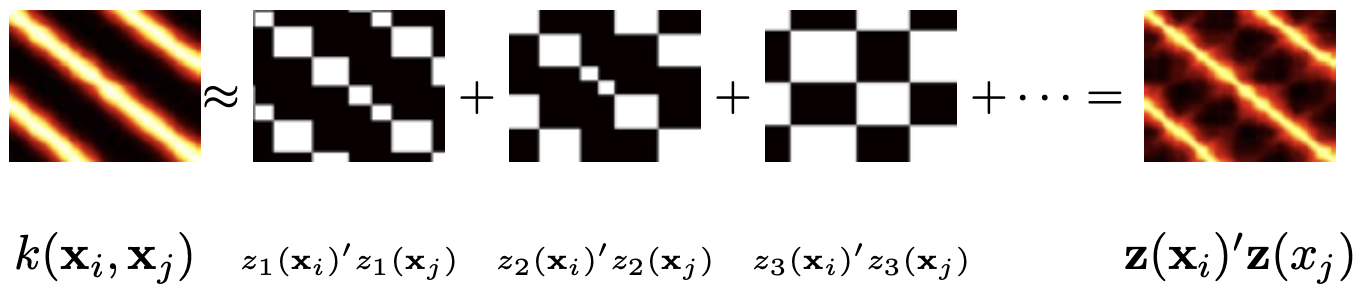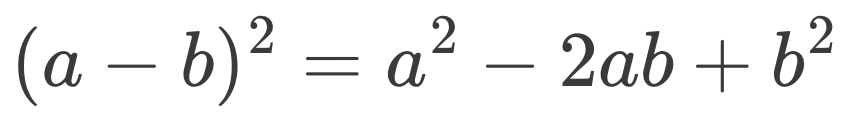Alex Smola
Blog
Projects
Papers
Alumni
Teaching
CV
Adventures in Data Land
Categories
All
(47)
acceleration
(1)
agentic coding
(2)
agents
(1)
Amazon
(1)
benchmark
(1)
big learning
(1)
Bloom filter
(1)
book
(1)
caching
(1)
classification
(1)
CMU
(1)
collaborative filtering
(2)
covariate shift
(1)
d2l
(1)
data privacy
(1)
distance
(1)
distributed learning
(2)
distributed synchronization
(1)
dot product
(1)
evaluation
(4)
fairness
(2)
fast transforms
(1)
feistel network
(1)
floating point
(1)
graphical models
(3)
graphs
(1)
hashing
(6)
hci
(2)
importance sampling
(1)
inference
(1)
infiniband
(1)
infrastructure
(1)
kernel
(4)
kernels
(1)
latency
(1)
LDA
(1)
linear algebra
(1)
linear function
(1)
llm
(2)
LLMs
(1)
MLSS
(4)
model selection
(1)
MXNet
(2)
networking
(1)
optimization
(4)
parameter server
(2)
Pittsburgh
(1)
Purdue
(1)
quantization
(1)
random features
(1)
random numbers
(1)
random projections
(2)
regularization
(1)
sampler
(1)
sampling
(2)
search
(1)
semiring
(1)
social networks
(1)
softmax
(1)
sparsity
(3)
statistics
(1)
stream
(1)
submodularity
(1)
trick
(2)
tutorial
(2)
voice
(2)
Weisfeiler Leman
(1)
why
(1)
workshop
(1)
Losing the thread
voice
evaluation
A bank’s voice agent has verified the caller and is reading out which accounts have a pending overdraft decision. The transcript below is from IHBench, verbatim.
Jul 6, 2026
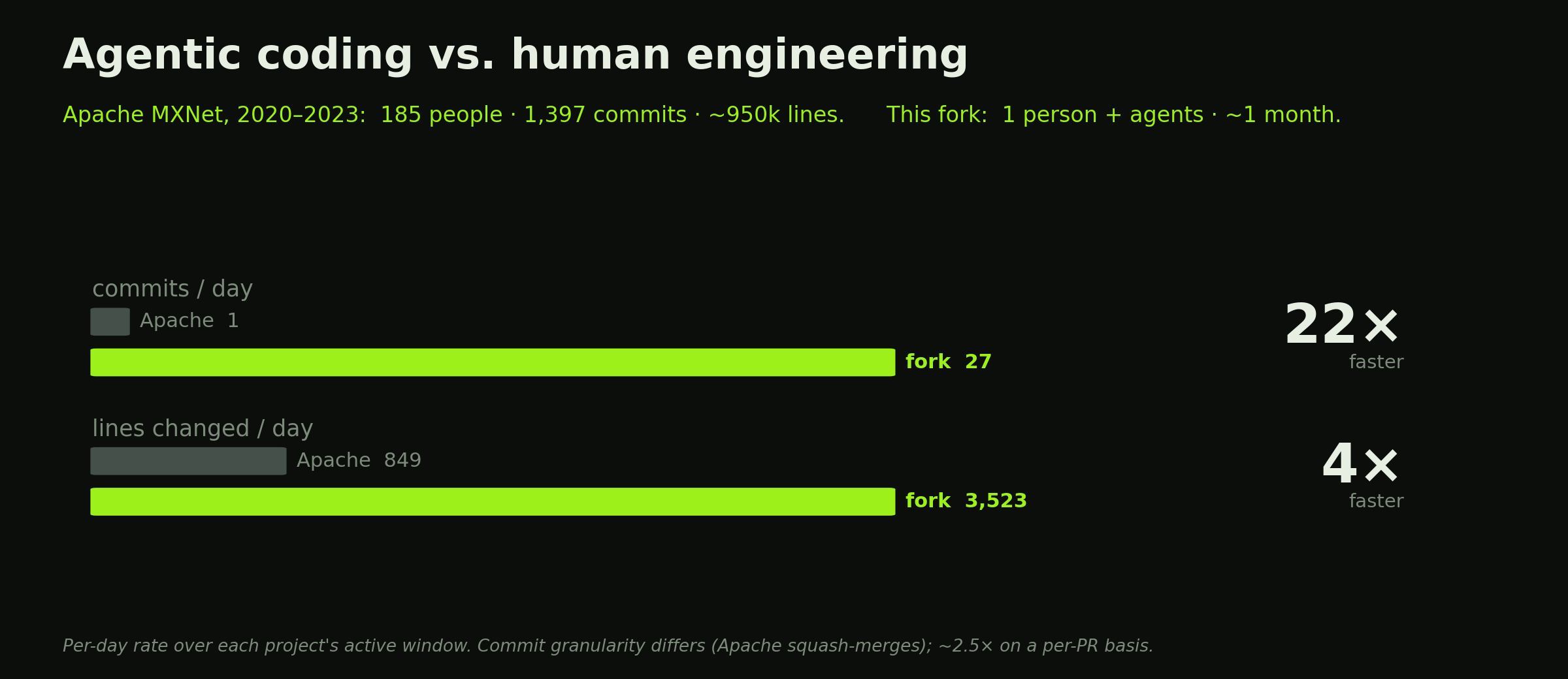
The autopsy: porting MXNet to Blackwell and Apple Silicon
MXNet
agentic coding
Last post was the story of dragging MXNet out of the Apache Attic, and the method I used to do it: run the tests, treat every failure as a clue, write a regression test for…
Jun 19, 2026
Raising MXNet from the Attic
MXNet
agentic coding
Apache projects don’t really die. They go to the Attic — and I mean that literally, the
Apache Attic
is a real place, the shelf where retired projects are filed away with a…
Jun 18, 2026
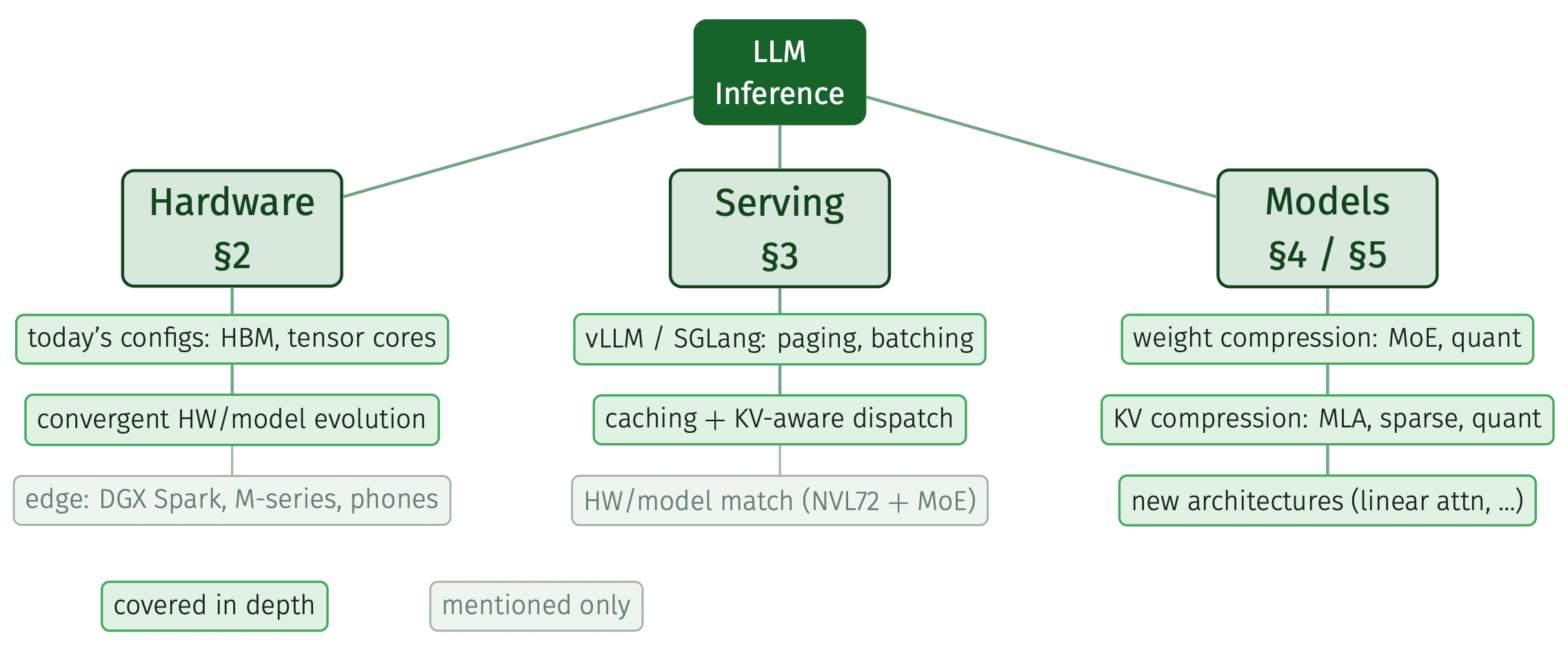
Efficiency in LLMs
MLSS
LLMs
inference
Next week I am teaching a tutorial on efficient LLM inference at the Machine Learning Summer School 2026 in NYC, hosted this year at Columbia University. The slides are…
Jun 13, 2026
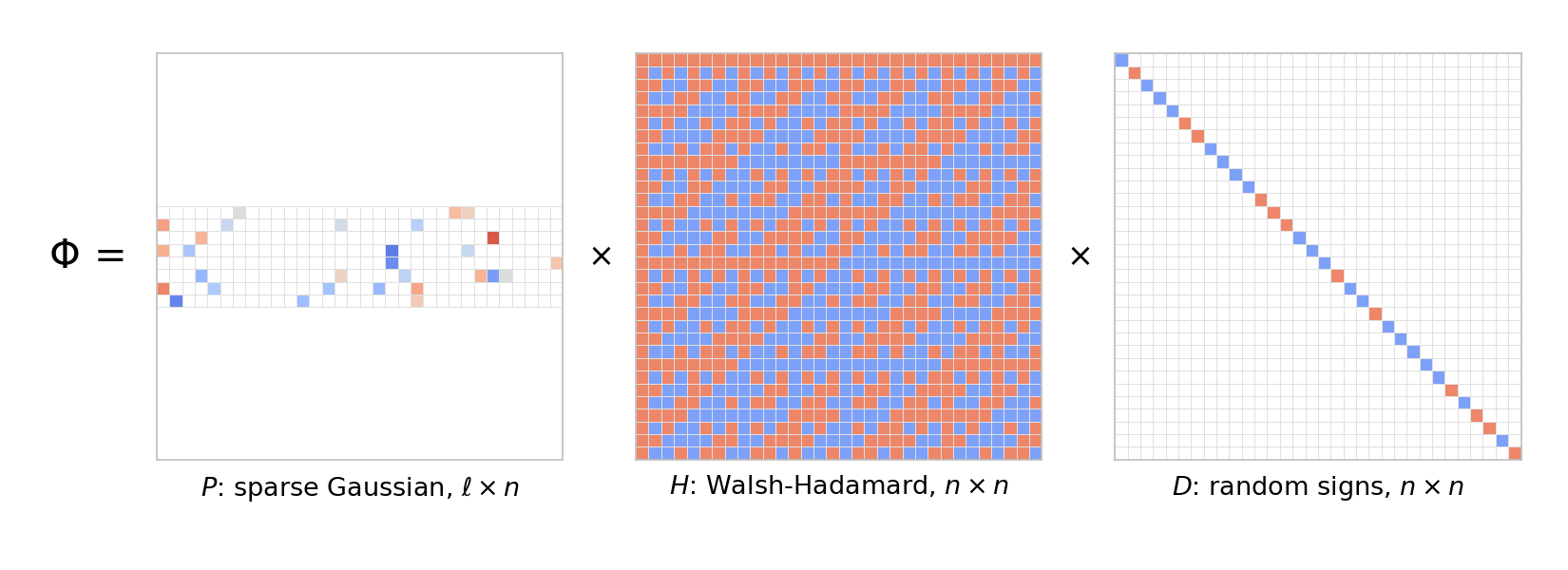
Fast projections require a PHD
random projections
fast transforms
Yesterday’s post closed with a conundrum: all three estimators assumed that computing
\(w^\top u\)
is cheap, yet a dense Gaussian projection to
\(\ell\)
dimensions costs
\(n\…
Jun 10, 2026
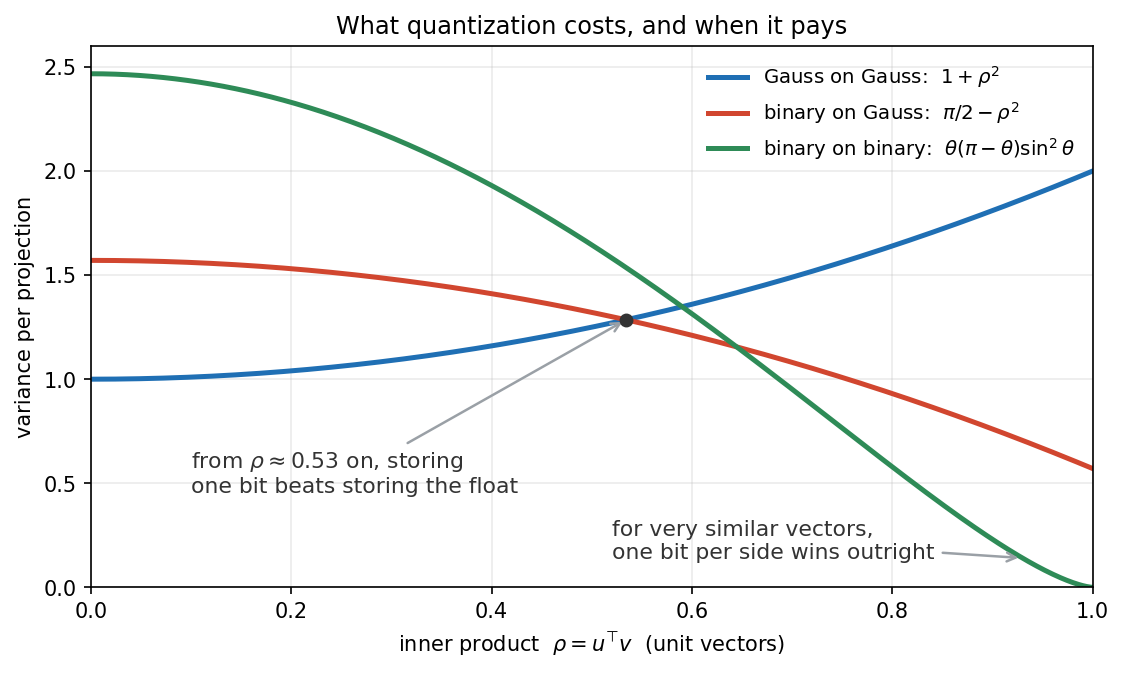
Random projections, three ways
random projections
quantization
A surprising number of posts on this blog secretly run on the same primitive. Hashing for linear functions estimates an inner product after scrambling coordinates. Random…
Jun 9, 2026
Digital humans
agents
voice
hci
When was the last time you enjoyed calling your cable company? You work through the phone tree, explain your problem to the first person, who moves you to a second person…
Jun 7, 2026
The effective sample size
statistics
importance sampling
Years ago I wrote about correcting covariate shift by reweighting your data. Your features come from the wrong distribution
\(q\)
, you care about a target
\(p\)
, so you…
Jun 2, 2026
ProactBench
evaluation
llm
benchmark
A few days ago I wrote about conversational proactivity: a model noticing what you disclosed but never asked about, and turning it into something useful. The running example…
Jun 1, 2026
What your assistant didn’t say
llm
evaluation
hci
A user has spent ten minutes preparing for a small art installation. The final exchange goes like this.
May 29, 2026
Beating
\(2^n - 1\)
for InfiniBand
networking
infiniband
infrastructure
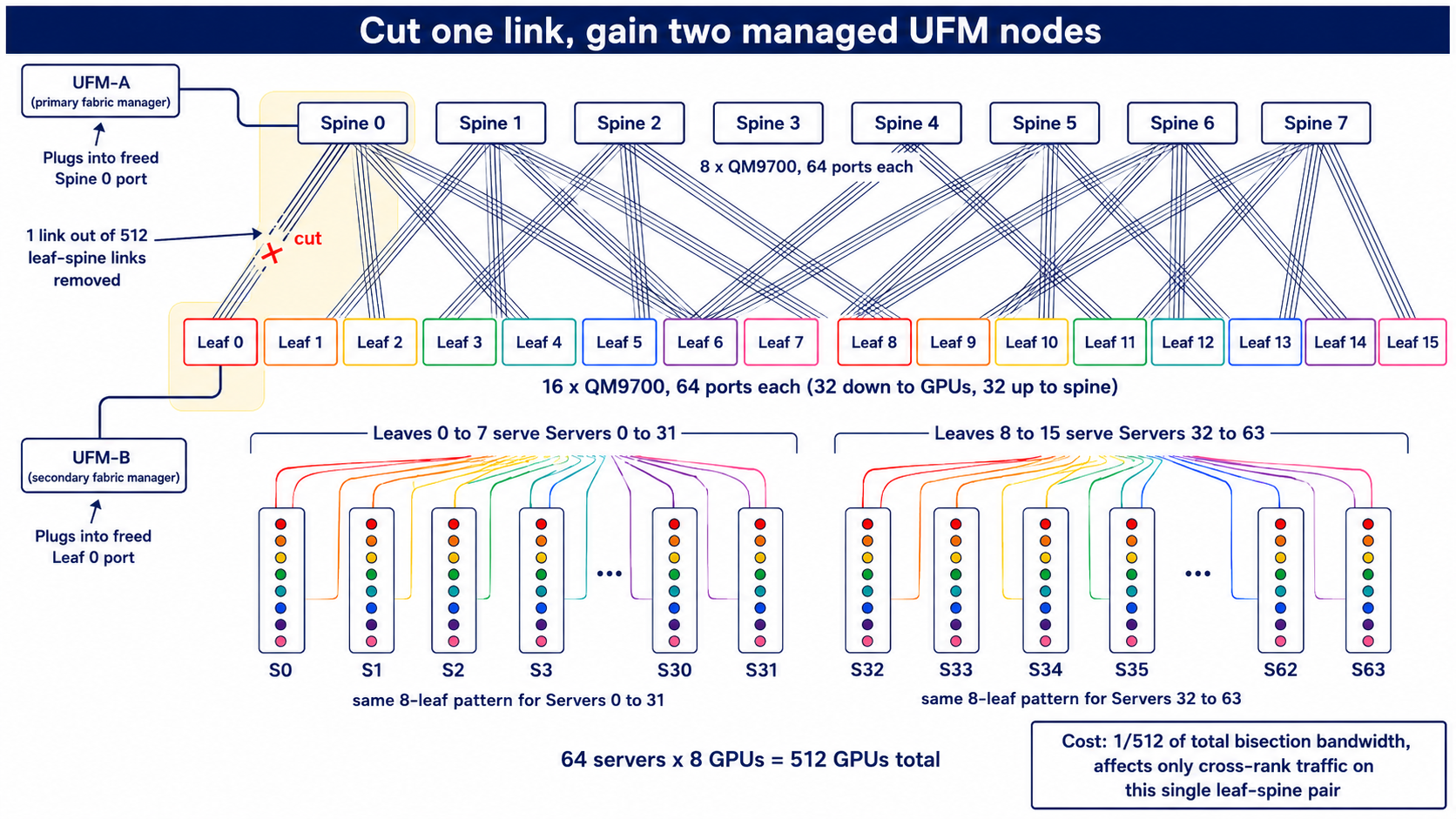
One of my favorite interview questions for network engineers (no longer, now that I’m about to spoil it): you have 512 GPUs across 64 servers, eight GPUs per box. Your…
May 27, 2026
Fair representations are pancakes
fairness
kernel
The natural reaction to the Pokémon theorem is to escape into representation learning. If finite scalar checklists cannot catch every fairness violation, then bake fairness…
May 26, 2026
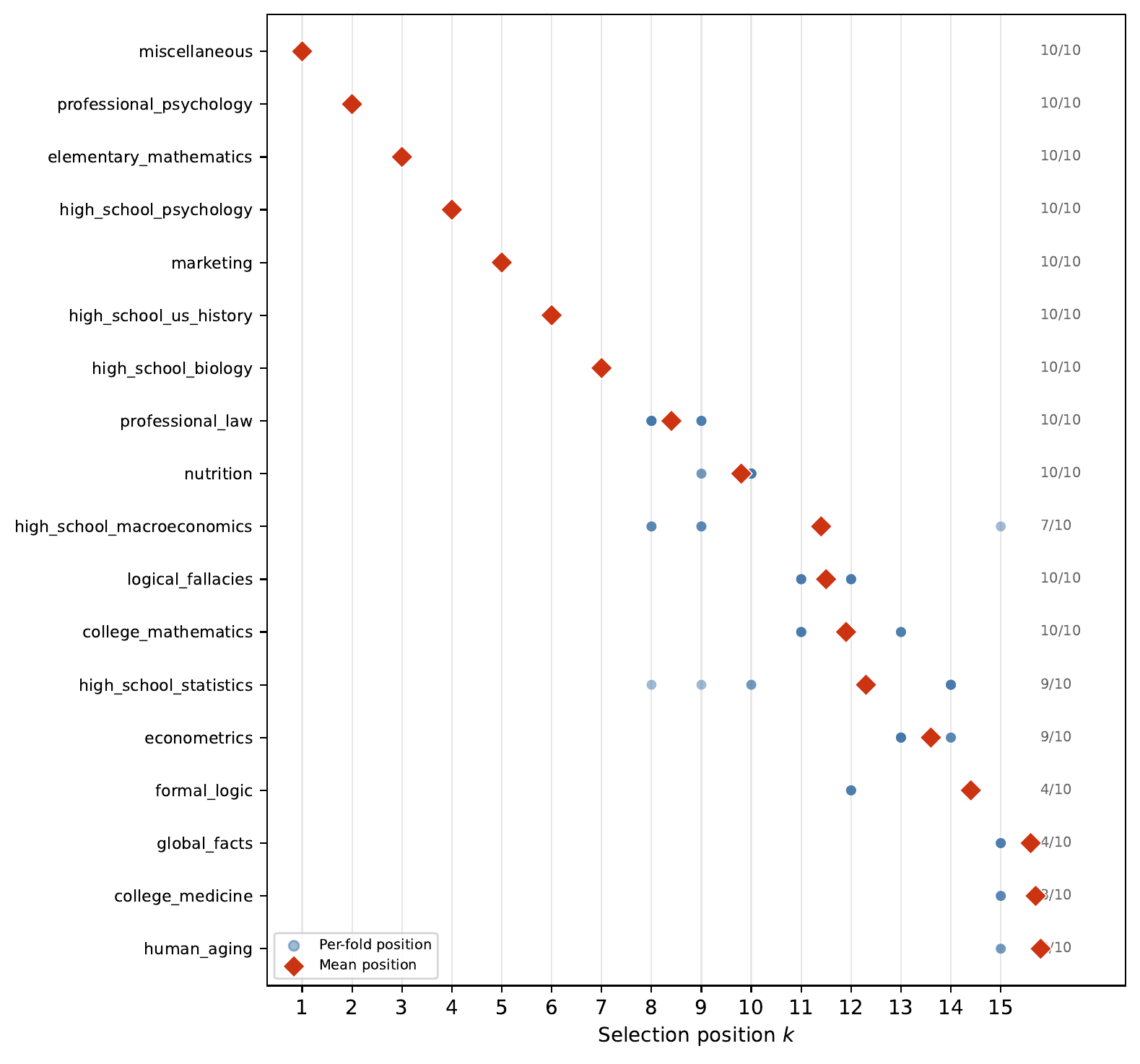
You don’t need all the benchmarks
evaluation
submodularity
Every time a new model comes out, somebody runs it on MMLU (57 subjects), MTEB (56 tasks), HELM, the Open LLM Leaderboard, AlpacaEval, LiveBench, BigCodeBench, WildBench, Are…
May 25, 2026
The Pokémon Theorem
fairness
kernel
If you have been near algorithmic fairness for the past decade, you already know the punchline: you cannot have all the things you want. Calibration, class-conditional…
May 25, 2026
Dive into Deep Learning
d2l
book
I’m happy to announce our new book project - Dive into Deep Learning. It’s still in beta stage, i.e. we’re still working on it. That said, I think that it’s good enough to…
Jan 15, 2019
Leaving CMU
CMU
Amazon
Dear Friends,
As some of you may have already heard, I’m leaving CMU to join Amazon, effective July 1, 2016. There I will be in charge of Amazon’s Cloud Machine Learning…
Jun 1, 2016
MLSS
Pittsburgh
Zico Kolter and I proudly announce the 2014 Machine Learning Summer School in Pittsburgh. It will be held at Carnegie Mellon University in July 7-18, 2014. Our focus is on…
May 15, 2014
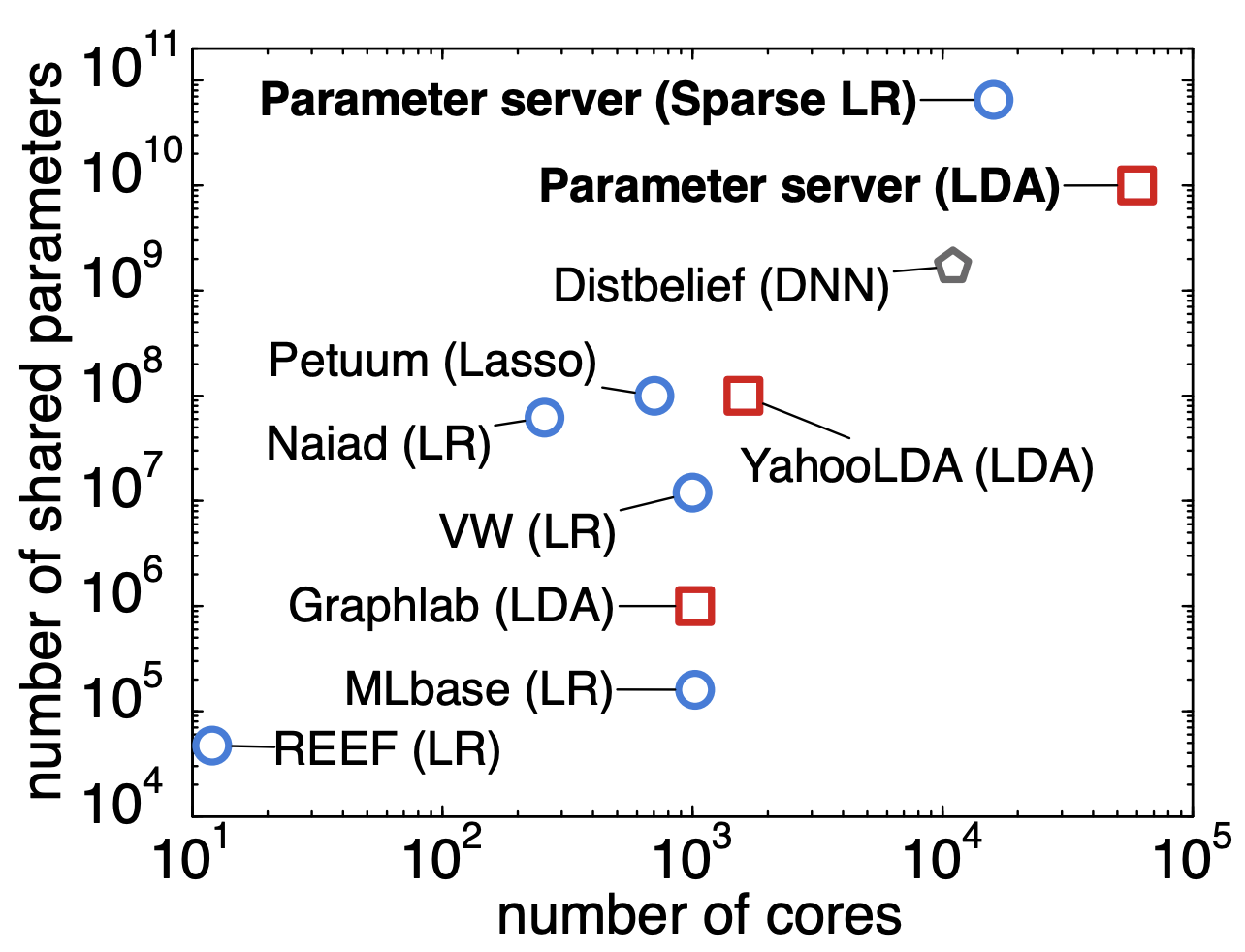
Distributing Data in a Parameter Server
parameter server
One of the key features of a parameter server is that it, well, serves parameters. In particular, it serves more parameters than a single machine can typically hold and…
Jan 15, 2013
100 Terabytes, 5 Billion Documents, 10 Billion Parameters, 1 Billion Inserts/s
parameter server
distributed learning
We’ve been busy building the next generation of a Parameter Server and it’s finally ready. Check out the OSDI 2014 paper by Li et al.; It’s quite different from our previous…
Dec 15, 2012
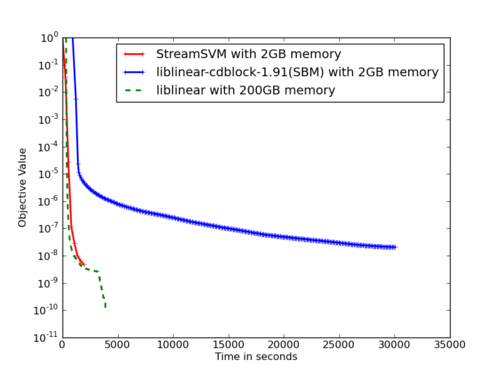
Beware the bandwidth gap - speeding up optimization
optimization
caching
Disks are slow and RAM is fast. Everyone knows that. But many optimization algorithms don’t take advantage of this. More to the point, disks currently stream at about…
Oct 15, 2012
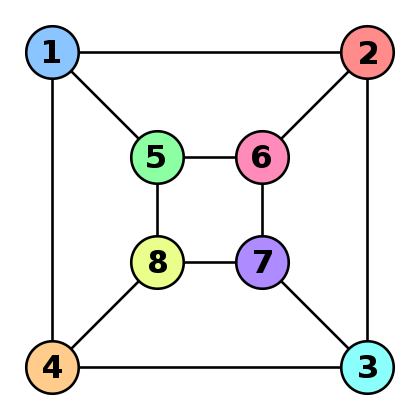
The Weisfeiler-Leman algorithm and estimation on graphs
Weisfeiler Leman
graphs
kernels
The Weisfeiler-Leman algorithm and estimation on graphs Imagine you have two graphs
\(G\)
and
\(G′\)
and you’d like to check how similar they are. If all vertices have…
Sep 15, 2012
In defense of keeping data private
data privacy
social networks
In defense of keeping data private This is going to be contentious. And it somewhat goes against a lot of things that researchers hold holy. And it goes against my plan of…
Aug 15, 2012
MLSS Purdue
MLSS
Purdue
The videos from MLSS 2011 in Purdue are now available online. Unfortunately the 2011 MLSS website is gone and with it all the playlists and PDFs. The only thing left is a…
Jul 15, 2012
Random numbers in constant storage
random numbers
hashing
Many algorithms require random number generators to work. For instance, locality sensitive hashing requires one to compute the random projection matrix
\(P\)
in order to…
Jun 15, 2012
tutorial
graphical models
The slides for the NIPS 2011 tutorial on Graphical Models for the Internet are online. Lots of stuff on parallelization, applications to user modeling, content…
May 15, 2012
The Neal Kernel and Random Kitchen Sinks
kernel
random features
So you read a book on Reproducing Kernel Hilbert Spaces and you’d like to try out this kernel thing. But you’ve got a lot of data and most algorithms will give you an…
Apr 15, 2012
Big Learning: Algorithms, Systems, and Tools for Learning at Scale
workshop
big learning
We’re organizing a workshop at NIPS 2011. Submission are solicited for a two day workshop December 16-17 in Sierra Nevada, Spain.
Aug 15, 2011
Introduction to Graphical Models
graphical models
MLSS
Here are the slides [Keynote, PDF] for a basic course on Graphical Models for the Internet that I’m giving at MLSS 2011 in Purdue that Vishy Vishwanathan is organizing. The…
Aug 10, 2011
Distributed synchronization with the distributed star
distributed synchronization
hashing
Here’s a simple synchronization paradigm between many computers that scales with the number of machines involved and which essentially keeps cost at
\(O(1)\)
per machine.…
Aug 5, 2011
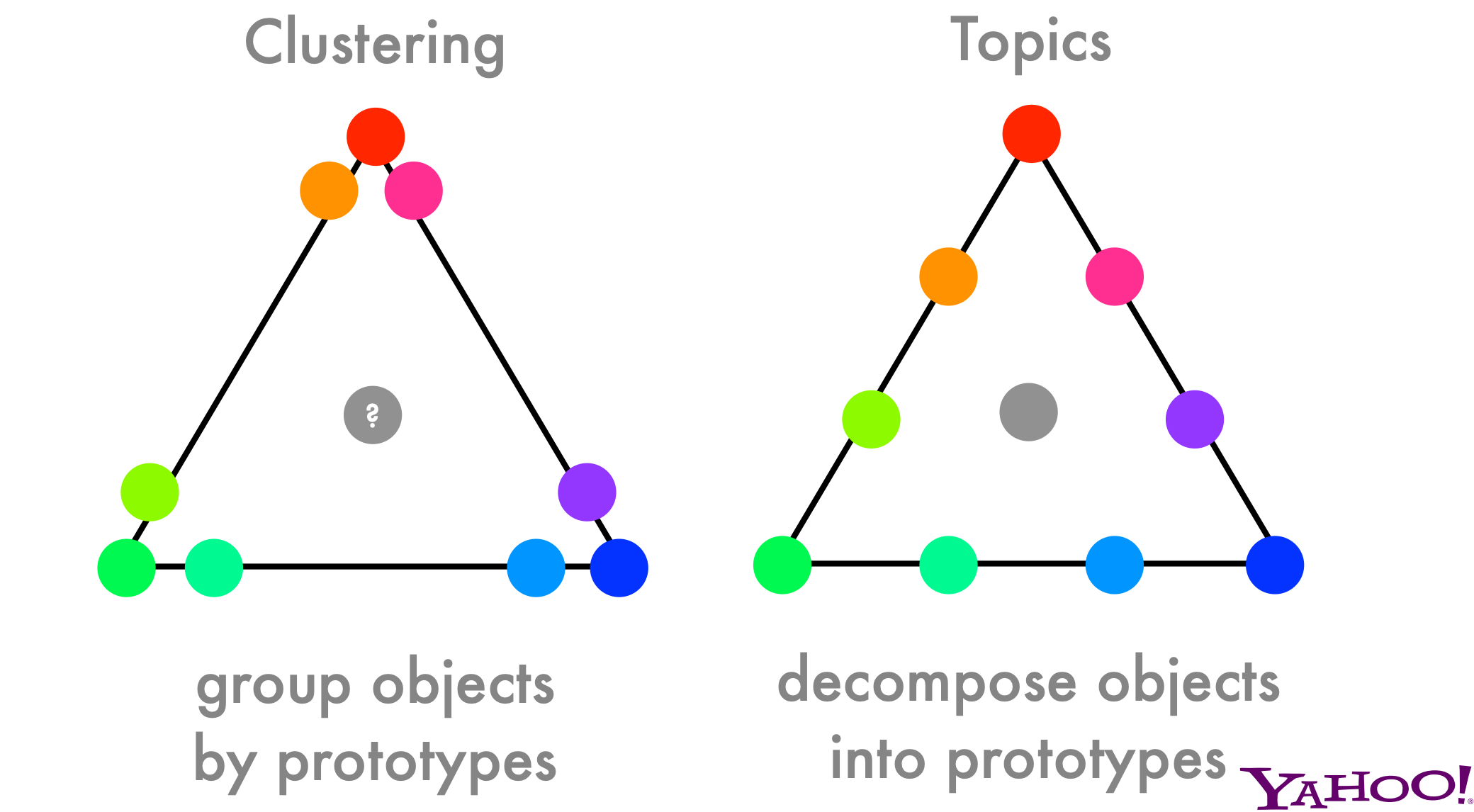
Speeding up Latent Dirichlet Allocation
LDA
sampler
The code to our LDA implementation on Hadoop is released on Github under the Mozilla Public License. It’s seriously fast and scales very well to 1000 machines or more (don’t…
Aug 1, 2011
Bloom Filters
Bloom filter
hashing
Bloom filters are one of the really ingenious and simple building blocks for randomized data structures. A great summary is the paper by Broder and Mitzenmacher, 2005. The…
Jul 30, 2011
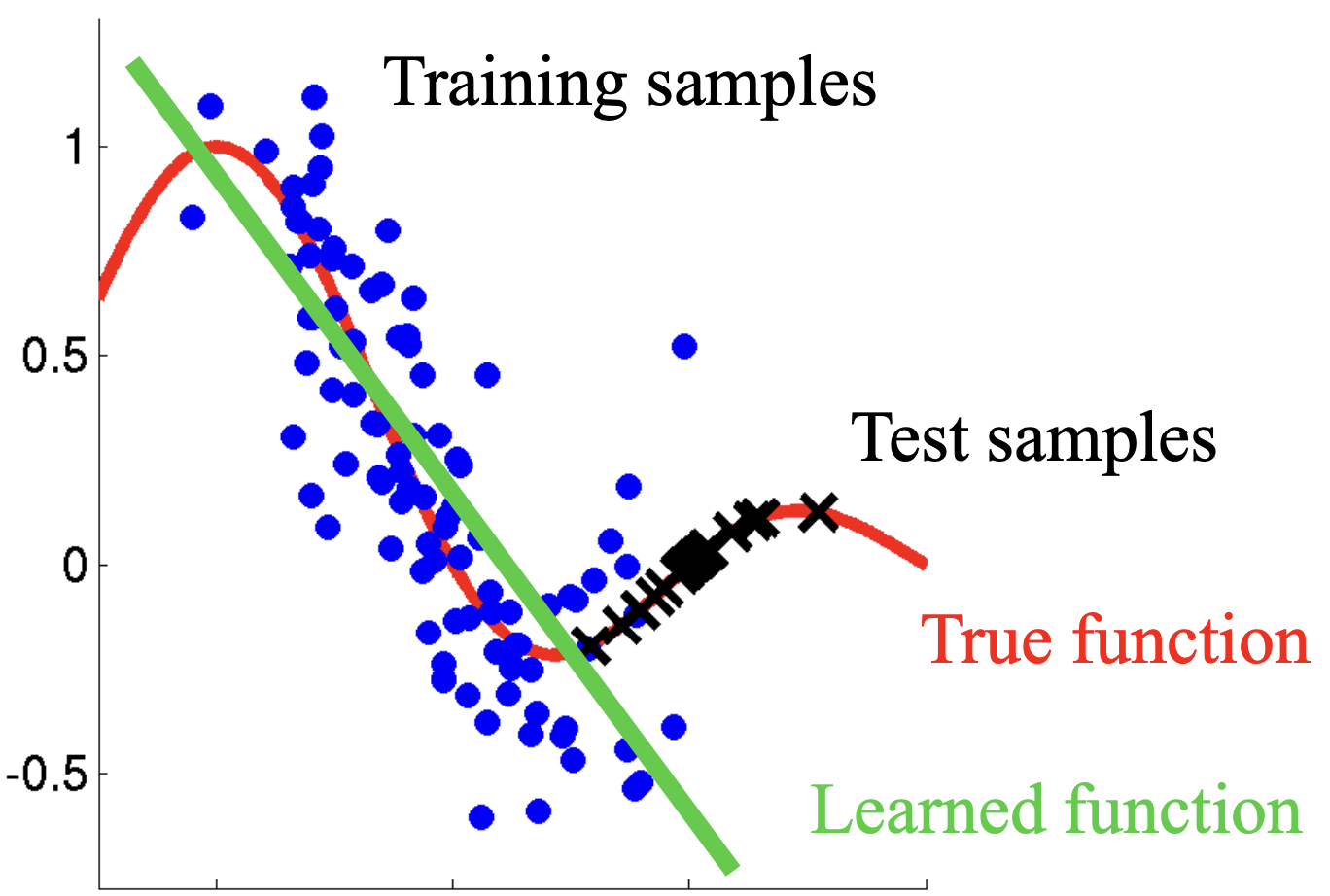
Real simple covariate shift correction
covariate shift
classification
Imagine you want to design some algorithm to detect cancer. You get data of healthy and sick people; you train your algorithm; it works fine, giving you high accuracy and…
Jul 25, 2011
graphical models
tutorial
Here are a few tutorial slides I prepared with Amr Ahmed for WWW 2011 in Hyderabad next week. They describe in fairly basic (and in the end rather advanced) terms how one…
Jul 20, 2011
Memory Latency, Hashing, Optimal Golomb Rulers and Feistel Networks
hashing
feistel network
latency
In many problems involving hashing we want to look up a range of elements from a vector where the elements are indicated by a hash function
\(h\)
. For instance, we might…
Jul 15, 2011
Collaborative Filtering considered harmful
collaborative filtering
search
Much excellent work has been published on collaborative filtering, in particular in terms of recovering missing entries in a matrix. The Netflix contest has contributed a…
Jul 10, 2011
Why?
why
Some readers might wonder why I’m writing this blog. Here’s an (incomplete) list:
Jul 5, 2011
Hashing for Collaborative Filtering
hashing
collaborative filtering
This is a follow-up on the hashing for linear functions post. It’s based on the HashCoFi paper that Markus Weimer, Alexandros Karatzoglou and I wrote for AISTATS’10. It…
Jul 1, 2011
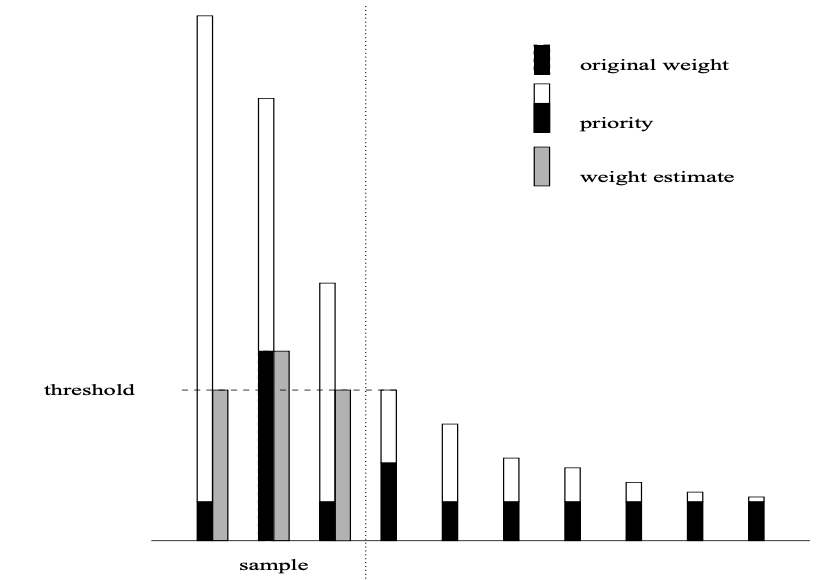
Priority Sampling
sampling
sparsity
Tamas Sarlos pointed out a much smarter strategy on how to obtain a sparse representation of a (possibly dense) vector: Priority Sampling by Duffield, Lund and Thorup, 2006.…
Jun 30, 2011
Random elements from a stream
sampling
stream
This is a classic trick when dealing with data streams. It shows how to draw a random element from a sequence of instances without knowing beforehand how long the sequence…
Jun 25, 2011
Sparsifying a vector/matrix
sparsity
Sometimes we want to compress vectors to reduce memory footprint or to minimize computational cost. For instance in deep learning we can accelerate operations by keeping only …
Jun 20, 2011
Log-probabilities, semirings and floating point numbers
floating point
softmax
semiring
Here’s a trick/bug that is a) really well known in the research community, b) lots of beginners get it wrong nonetheless, c) simple unit tests may not detect it and d) it…
May 1, 2011
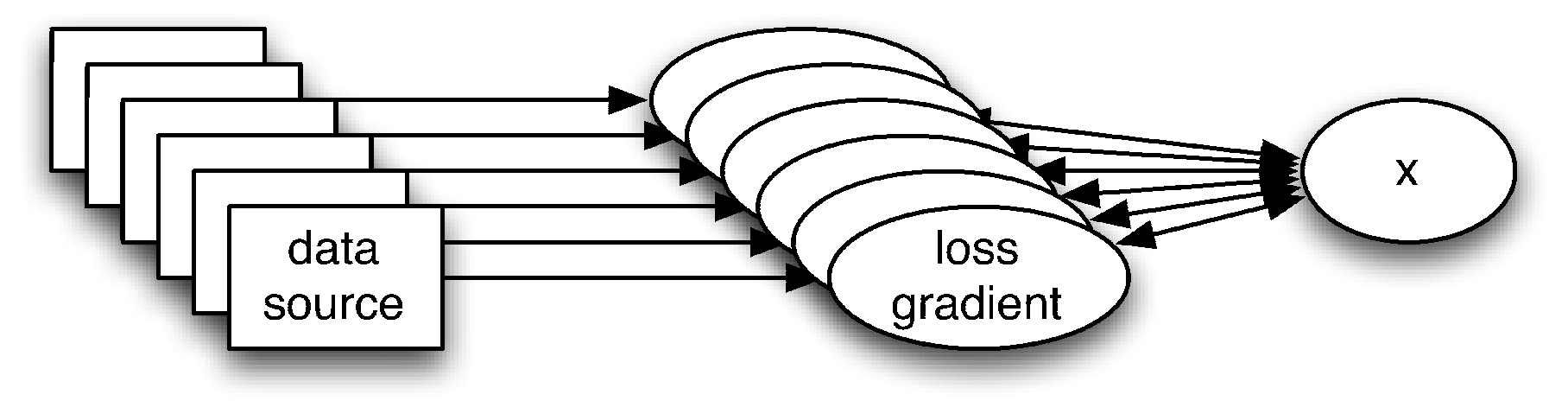
Parallel Stochastic Gradient Descent
distributed learning
optimization
Here’s the problem: you’ve optimized your stochastic gradient descent library but the code is still not fast enough. When streaming data off a disk/network you cannot exceed…
Apr 1, 2011
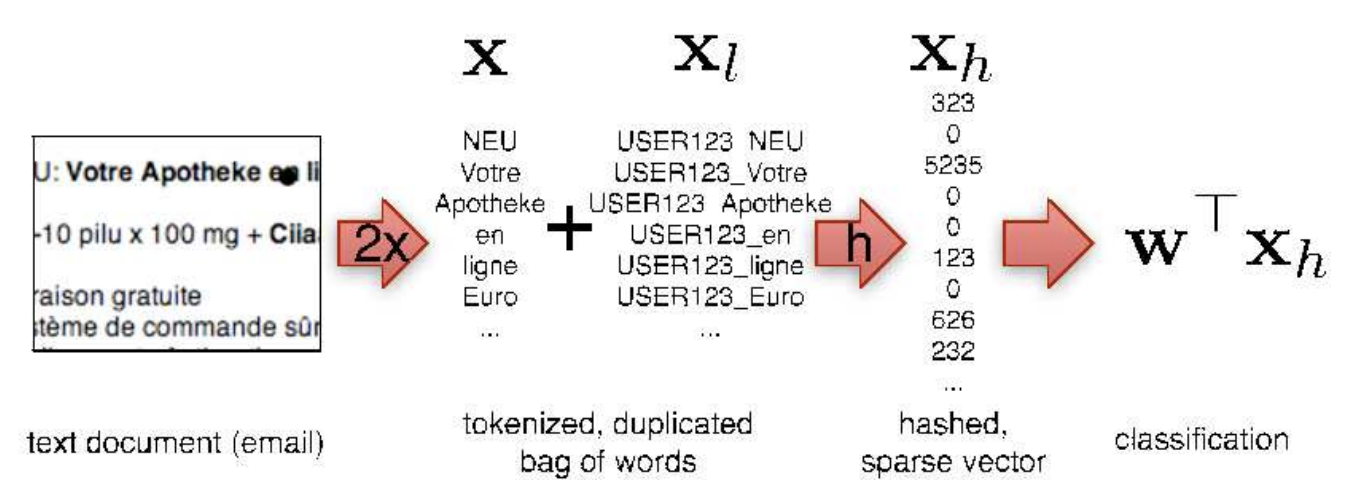
Hashing for Linear Functions
linear function
hashing
This is the first of a few posts on hashing. It’s an incredibly powerful technique when working with discrete objects and sequences. And it’s also idiot-proof simple. I…
Mar 1, 2011
In Praise of the Second Binomial Formula
distance
dot product
linear algebra
Here’s a simple trick you can use to compute pairs of distances: use the second binomial formula and a linear algebra library. These problems occur in RBF kernel…
Jan 1, 2011
Lazy updates for generic regularization in SGD
sparsity
optimization
Yesterday I wrote about how to do fast stochastic gradient descent updates for quadratic regularization. However, there are lots more regularizers which one would want to…
Nov 12, 2010
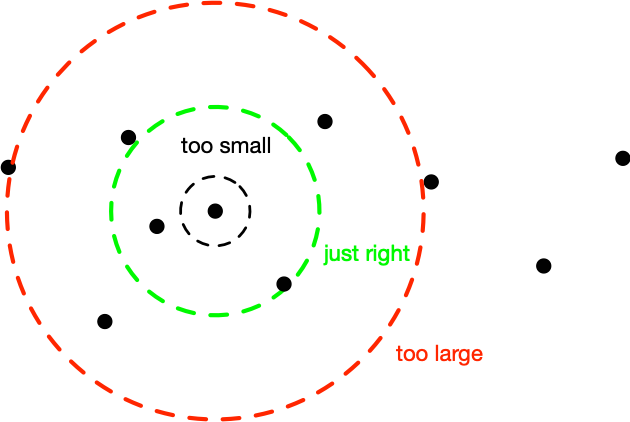
Easy Kernel Width Selection
kernel
trick
model selection
This is an idea that was originally put forward by Bernhard Schölkopf in his thesis: Assume you have an RBF (radial basis function) kernel and you want to know how to scale…
Oct 12, 2010
Fast quadratic regularization for online learning
optimization
acceleration
regularization
trick
After a few discussions within Yahoo I’ve decided to post a bunch of tricks here. A lot of these are well known. Some others might be new. They’re small hacks, too small to…
Jan 15, 2010
No matching items