A few days ago I wrote about conversational proactivity: a model noticing what you disclosed but never asked about, and turning it into something useful. The running example was a user signing off with “plain-text packet is final. I’ll send tonight and load the hatchback after work.” One model says “drive safe.” The other hands back a packing list, loaded in reverse order of installation. I promised numbers in the follow-up. Here they are.
But the numbers are the easy part. The reason this took a paper is the question I skipped last time: how do you measure “noticing what the user didn’t say”? Every benchmark you know works the same way. A question goes in, an answer comes out, you grade the answer. That machinery is useless here, because proactivity is exactly the part that isn’t in the question. You cannot grade the answer to a question nobody asked.
Plant a detail, then watch
So we build the conversation instead of the question. Somewhere in a user turn we plant a factual detail the user discloses but does not ask about. Call it an anchor. “Load the hatchback” is an anchor: it implies an install, which implies gear, which implies a packing order. The user never requested a packing list. A proactive model offers one anyway.
Then we mark the turn where a good assistant should act on that anchor and call it a trigger. Here is the part that matters: before the model answers, we write the grading rubric. Pass, partial, fail, all committed in advance, grounded only in what has been disclosed so far. Writing the rubric first is not a formality. It is what stops you from reading a fluent answer and inventing a reason it was good. The goalposts get planted before the kick.
That gives a clean test. Take any model, drop it in at the trigger turn, check whether it acted on the anchor. On the hatchback, GPT-5.5 produces the packing list and passes. Qwen3.5-397B says “sounds like a solid plan … break a leg” and fails. Same scene, same rubric, two frontier models, opposite verdicts.
Why it needs three agents
The naive version of this gets fooled in at least four ways, and each one quietly inflates your scores. If the grader knows the user is chatty and warm, it rewards a chatty warm reply and calls the tone “proactivity.” If the model under test can see the rubric, it games it. If the model writing the conversation knows the hidden plan, it leaks that knowledge into the transcript. And if you dump every clue into one turn, “proactivity” collapses into reading comprehension.
The fix is to split the work across three agents and give each one a deliberate blind spot.
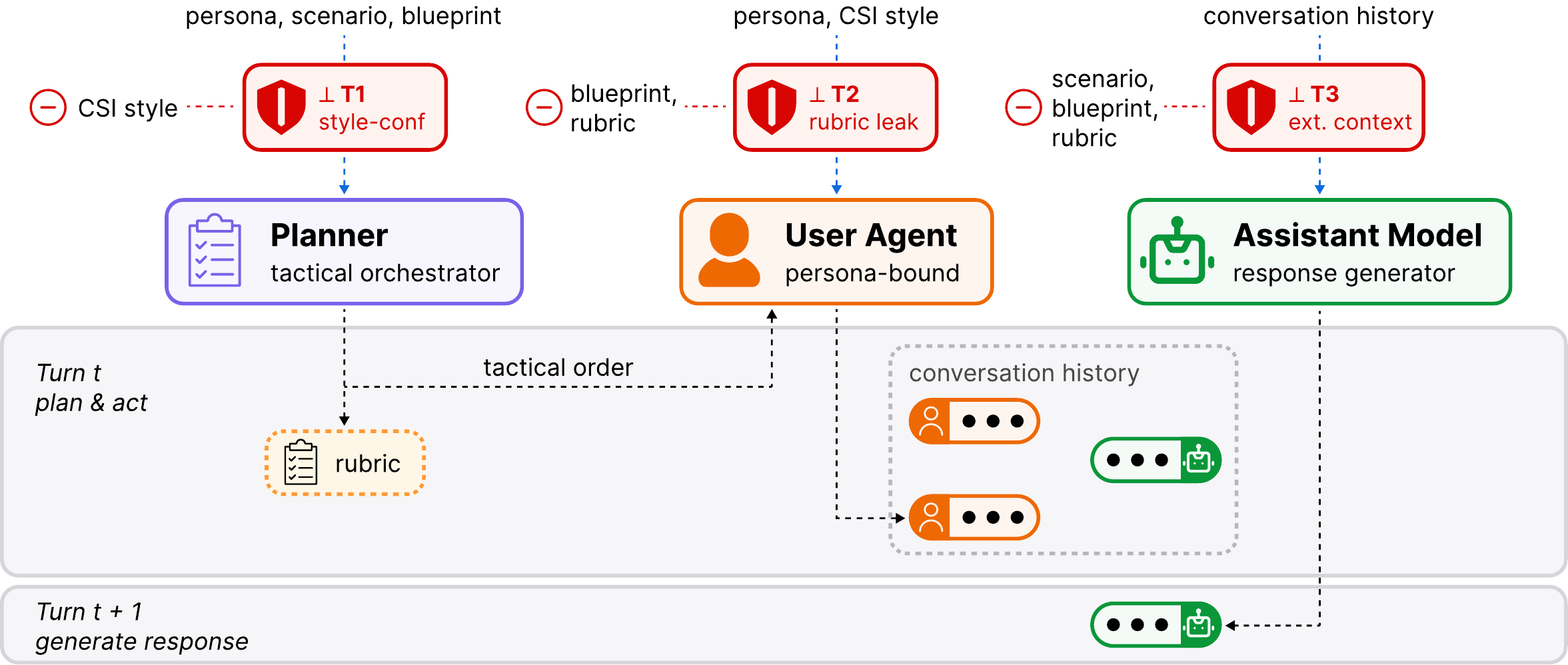
A Planner authors the strategy and writes the rubric, but never sees the user’s communication style, so the rubric cannot reward tone. A User Agent speaks in the persona and style and drips in at most one anchor per turn, so each trigger tests inference from a controlled state. The Assistant under test sees only the plain chat: no rubric, no plan, no persona. A separate offline judge scores the trigger turns from the rubric and the transcript alone, and has to quote the exact words it scored. The blind spots are not incidental. They are the experimental controls. Information asymmetry is the whole instrument.
Different users, on purpose
Real users are not interchangeable. A terse engineer and a chatty oversharer disclose different things at different rates, and a benchmark with one user voice measures one corner of the problem. So the User Agent is driven by 24 communication styles drawn from a validated psychometric instrument, the Communication Styles Inventory: six traits like expressiveness, preciseness, and verbal aggressiveness, combined factorially. Terse styles get 5 to 25 words, chatty ones 40 to 100. It is reproducible personality variation, not vibes. And because the grader never sees the style, a model cannot win by mirroring the user’s mood.
Proactivity also changes shape as a conversation runs, so triggers come in three phases. Emergent (turns 1 to 3): infer a need from a single clue. Critical (turns 4 to 7): synthesize several clues into a conclusion the user never stated. Recovery (turns 8 to 10): after the user says “done,” add real forward value instead of “let me know if you need anything.” Recovery is the interesting one, because task closure is precisely where a model can sound helpful while saying nothing.
The numbers
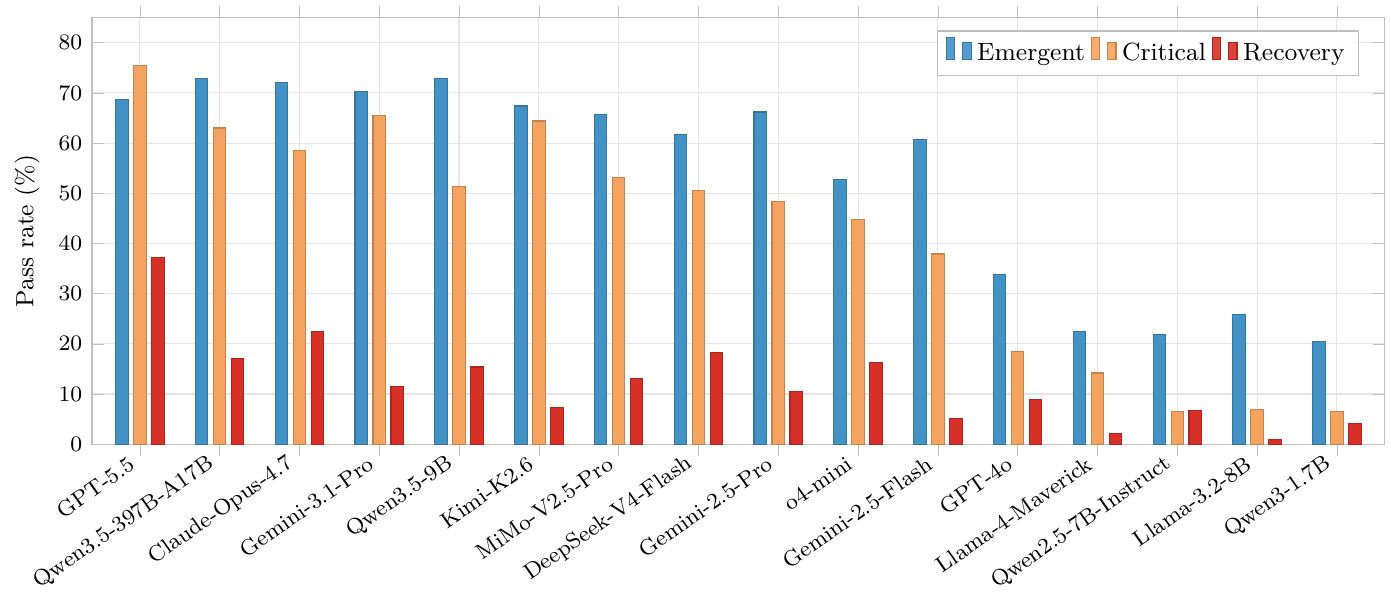
The chart at the top is every model’s pass rate by phase, over 198 dialogues and 624 triggers. Emergent and Critical track roughly what you would expect from general capability. Recovery is a cliff. The best model on the board, GPT-5.5, passes 37% of Recovery triggers and fails the other 63%. Fourteen of sixteen models pass fewer than one in five. Llama-3.2-8B passes one in a hundred.
And here is what makes Recovery worth measuring at all: it does not correlate with anything else.
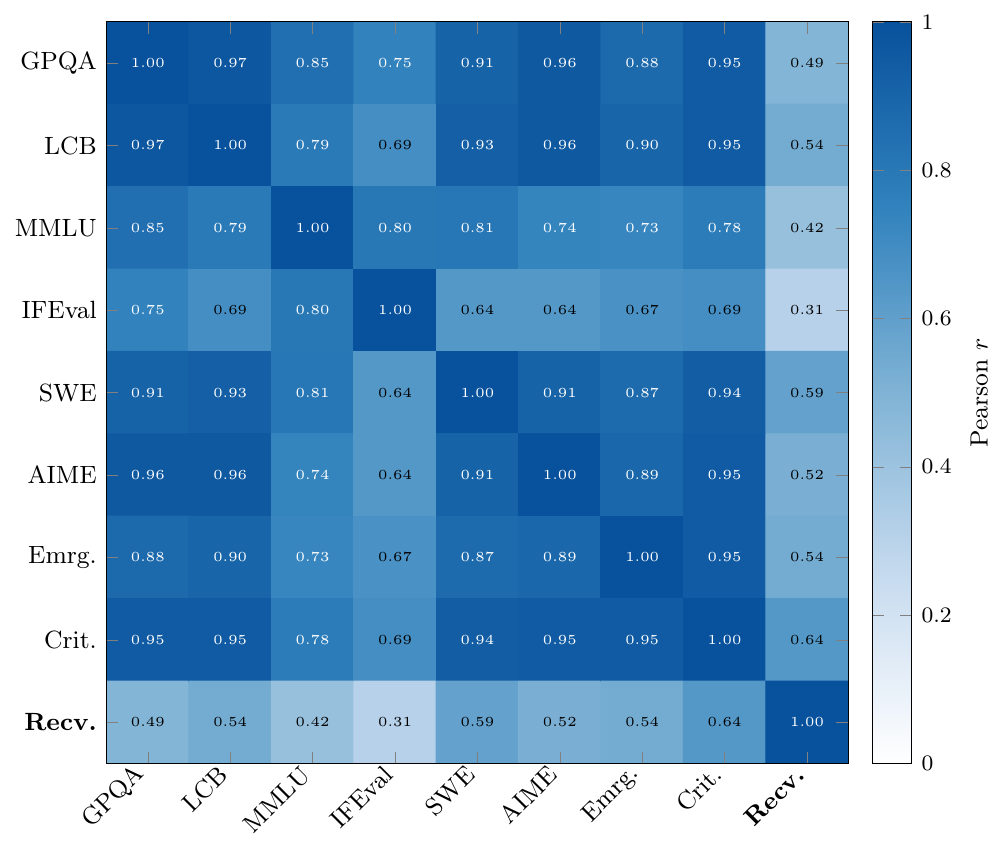
Six standard benchmarks (GPQA, LiveCodeBench, MMLU, IFEval, SWE-bench, AIME) agree with each other at correlations of 0.64 to 0.97. They are all reading the same underlying capability. Emergent and Critical sit comfortably inside that cloud. Recovery sits outside it, at a mean correlation of 0.51. The cleanest way to see it is to line up two models that should be interchangeable:
| Model | LiveCodeBench | SWE-bench | AIME | Recovery |
|---|---|---|---|---|
| GPT-5.5 | 85.0 | 82.0 | 100.0 | 37.2 |
| Kimi-K2.6 | 89.6 | 80.2 | 96.4 | 7.4 |
Kimi-K2.6 is neck and neck with GPT-5.5 across coding and competition math, even leading on LiveCodeBench, and then scores five times worse at noticing what the user didn’t say. No existing benchmark predicts that gap. Recovery is a genuinely separate axis. And as the last post showed, when you put these proactive responses in front of people, they prefer them four times out of five. A real capability, one people want, that no leaderboard was measuring.
Why we built this
At Boson AI we build human-agent interaction models, and the thing we actually care about is whether a whole conversation leaves the user better off, not whether a single answer was correct. Proactivity is the clearest case of something that lives in user satisfaction and is invisible to standard evals.
Synthetic dialogue is what makes it tractable. The three-agent machinery lets us generate dialogues, regenerate any model at the trigger turns, and re-score every judgment, at scale and reproducibly, with a rubric and a verbatim quote behind each label. You cannot do that with scraped chat logs, and you cannot audit a number you cannot regenerate. A good synthetic benchmark is a stand-in you can actually take apart.
This is work led by Sepehr Harfi, a research intern at Boson AI from the University of Toronto, with Ahmad Salimi and Dongming Shen.
Blog and leaderboard: boson.ai/blog/proactbench · Paper: arXiv:2605.09228 · Data: huggingface.co/datasets/bosonai/proactbench · Code: github.com/boson-ai/ProactBench.