
One of my favorite interview questions for network engineers (no longer, now that I’m about to spoil it): you have 512 GPUs across 64 servers, eight GPUs per box. Your switches are NVIDIA Quantum-2 class, MQM9700, sixty-four 400Gb/s NDR ports each. Wire it for full cross-sectional bandwidth. How many switches, what topology, and where do you put the fabric manager?
The textbook part is a two-tier fat tree, also known as spine and leaf. With 64-port switches, split each leaf into 32 ports facing GPUs and 32 ports facing the spine. That gives 16 leaf switches (\(16 \times 32 = 512\) endpoints) and 8 spine switches (each leaf sends \(32/8 = 4\) links to each spine; each spine ends up with \(16 \times 4 = 64\) down, filling the box). Bisection is full, switch count is 24. So far, so easy.
Two ways to wire the GPUs to the leaves
The lazy answer groups by server: take 4 servers, plug all \(8 \times 4 = 32\) NICs into one leaf. Everything on those four boxes lives on one switch. The problem is that within a single server, the GPUs already talk over NVLink at much higher bandwidth than IB will ever give you. The fabric exists to move data between servers, not within them. Putting four servers’ worth of intra-node traffic on one leaf optimizes for traffic that doesn’t happen. Worse, in collectives most of the GPU-to-GPU traffic is rank aligned: GPU0 talks to GPU0, GPU7 talks to GPU7. Group-by-server puts every rank on every leaf, so all of that rank-aligned traffic crosses the spine.
The rail-optimized layout flips this. Group by rank. All sixty-four GPU0s across the cluster go to leaf 0, all sixty-four GPU1s to leaf 1, and so on. Since we have 32 ports per leaf facing endpoints, each rank actually splits into two leaves of 32, so 16 leaves total, the same count as before. Any all-reduce within a rank stays leaf-local. Cross-rank traffic, the minority, climbs to the spine. This is how every serious training cluster gets wired, the NVIDIA SuperPOD reference architecture included.
So where do the UFM nodes go?
Quantum-class IB switches are unmanaged. You need a Unified Fabric Manager appliance to discover the topology, compute routes, monitor link health, and do everything the closed switch ASIC will not do for itself. Two UFM nodes for fault tolerance, hanging off different switches so one switch failure does not take both out.
The cluster as designed has zero slack. Every leaf port is a GPU, every spine port is a leaf uplink. This is where the bad options start.
Bad option 1: drop a server
Sacrifice one server, free 8 leaf ports (one per rank, on 8 different leaves). Plug two UFMs in. Done. The cluster is now 504 GPUs. Any 3D-parallel placement that wanted 64 servers, or any clean power of two in any dimension, gets to be ugly. You also paid for a 64th server you can’t fully use (as suggested by a vendor).
Bad option 2: add a core switch
Buy a third tier. A core switch above the spine frees 16 ports on the spines (the spines now uplink to core), and you hang the UFMs off there. This works. It costs you a switch, a rack of cabling, a few hundred watts, and it breaks the symmetry. Multipath routing on a regular fat tree is a beautiful thing. Hanging an asymmetric appliance off the top makes everyone’s life harder. Also, you bought a switch (also suggested by a vendor).
The actually good option
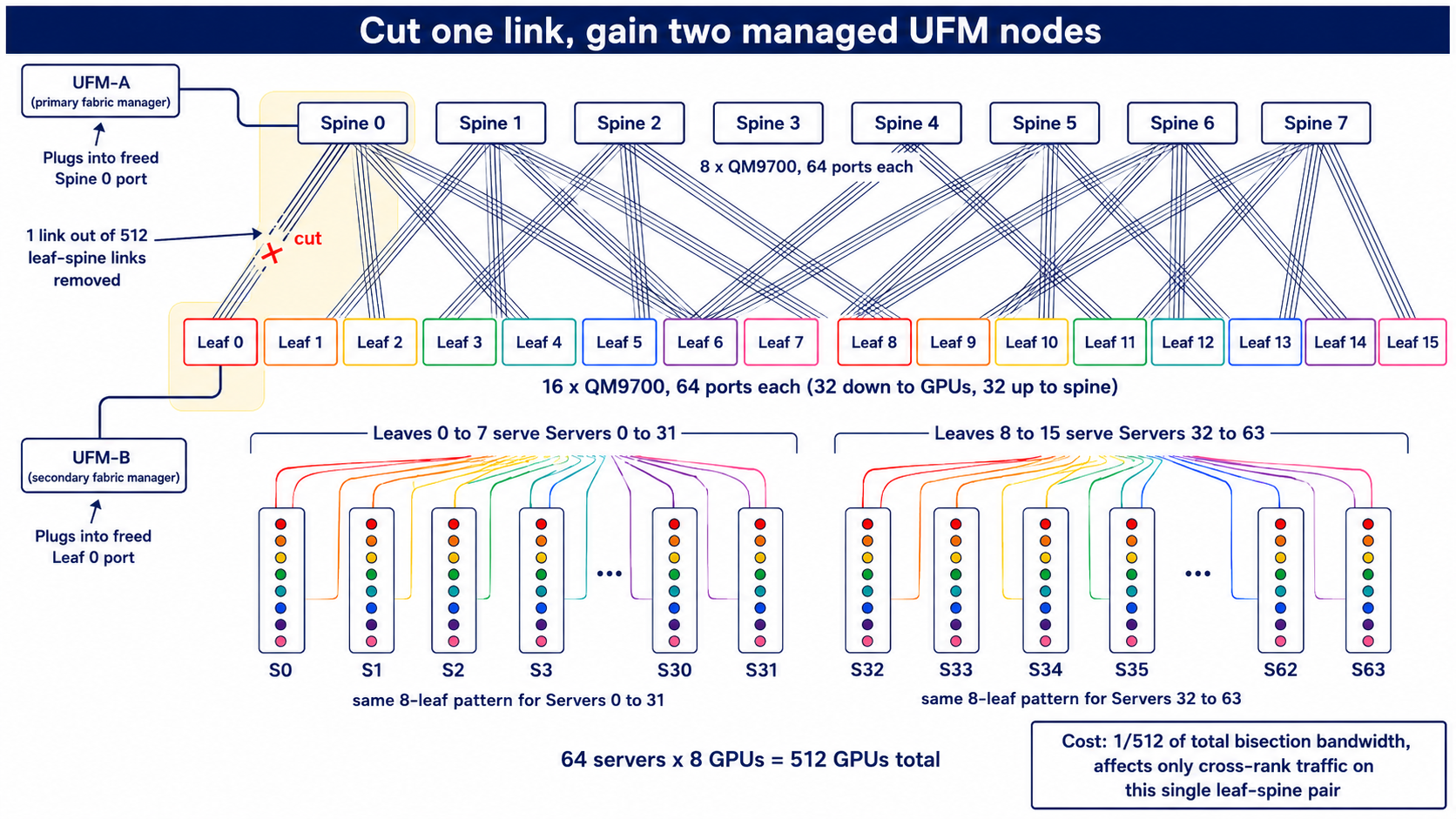
Here’s what we did at Boson AI: cut one cable between a leaf and a spine. Plug a UFM into the freed leaf port. Plug a second UFM into the freed spine port. Done.
What did that cost? One leaf-spine pair now has 3 links instead of 4, so the bandwidth between that specific pair is down 25%. Averaged across all \(8 \times 16 = 128\) leaf-spine pairs, you lost \(1/512\) of total cross-sectional capacity. The penalty only shows up when (a) you are running close to all 64 servers, (b) the traffic actually traverses that one degraded pair, and (c) the traffic is cross-rank, so it had to use the spine at all. In a rail-optimized topology, criterion (c) already excludes most of the load. In practice the oversubscription is invisible.
You keep 512 = \(2^9\) GPUs. You keep the symmetric uniform fat tree. You spend no extra hardware. You get two redundant fabric managers on physically distinct switches. The whole thing is a one-cable change.
Going to \(9 \cdot 2^n\)
Quantum-3 switches in the Q3400 family come with \(144 = 12 \cdot 16\) ports. As such, the natural cluster sizes land on \(9 \cdot 2^n\) GPUs instead of pure powers of two. As it turns out (thanks to Semianalysis for pointing this out), NVIDIA listened and added a dedicated UFM port to the switches.
At the same time, they disabled the possibility of running UFM on managed Quantum-2 switches. In case you wonder whether IB forwarding across Ethernet might be possible, this unfortunately doesn’t work for control signals.