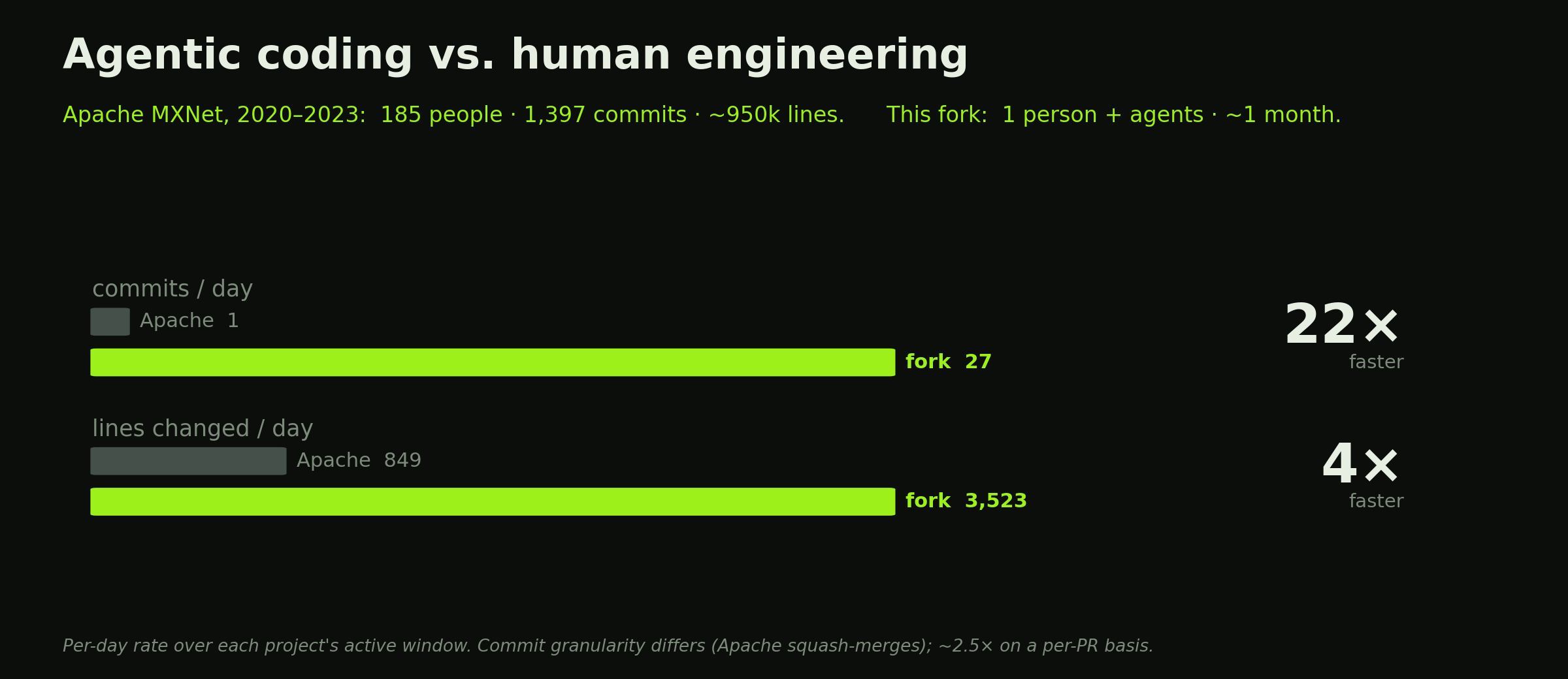
Last post was the story of dragging MXNet out of the Apache Attic, and the method I used to do it: run the tests, treat every failure as a clue, write a regression test for each bug, and let the agents do the legwork. This post is the autopsy — the specific things that were rotting, and what it took to stitch each one back together, minus a few limbs (e.g. TVM). It came to about 98 pull requests and 879 commits over a month, and the result is three pip-installable wheels: CUDA 13 / Blackwell, x86-64 Linux CPU, and native Apple Silicon CPU (you’ll need to install from GitHub, though).
One idea carries the whole post, and I made the case for it last time, so I’ll just restate it: in a deep learning library, the tests are a key part of the specification. A dead framework still compiles and still imports; what it has forgotten is how to be correct, and the only record of correct is the test suite. Everything below is something a test caught.
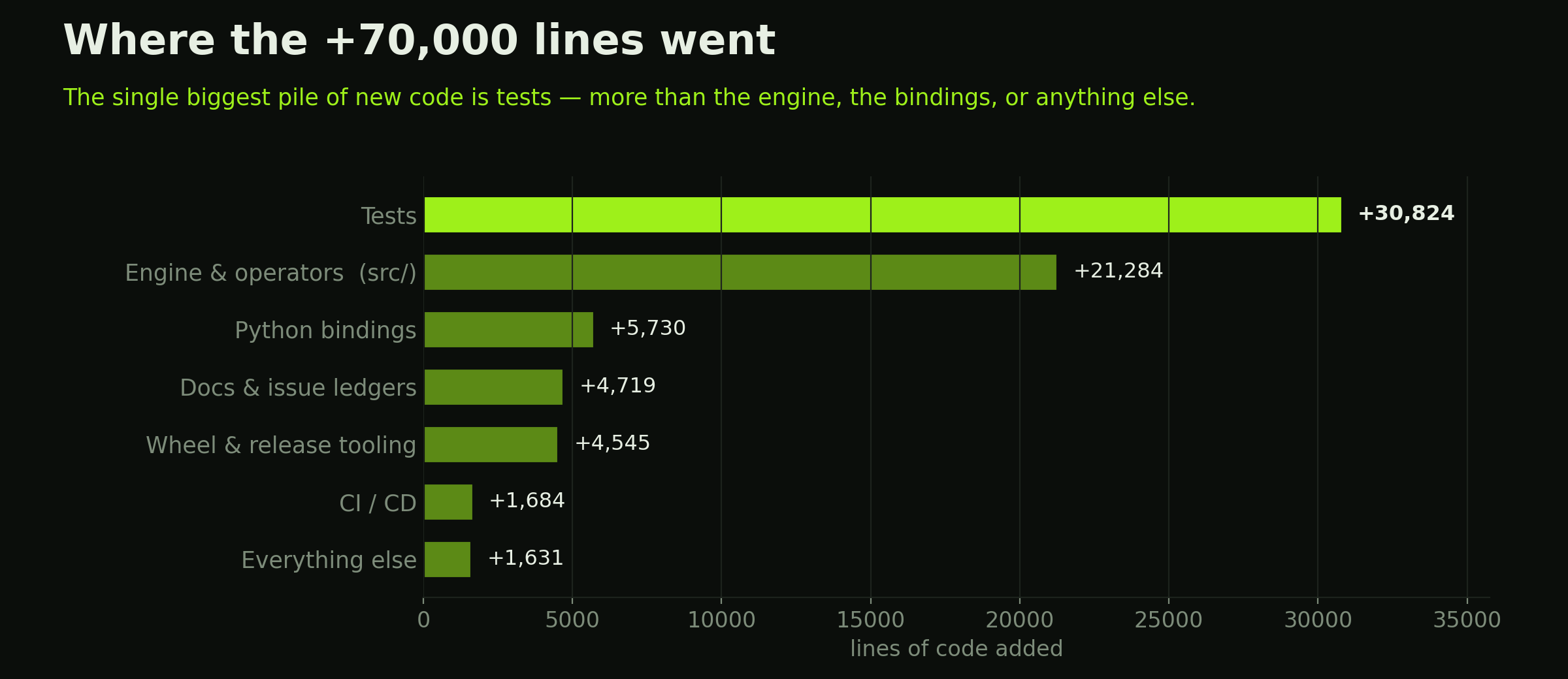
That isn’t an accident of accounting. The rule was one regression test per bug, so the test directory grew faster than anything else — it is where the recovered knowledge is written down.
The ledger
The bookkeeping grew its own taxonomy over the month, which is worth a paragraph because it shows the work maturing. Early on, the agents filed findings as B- (bugs), F- (fragility), and S- (smells), right in the commit messages. The middle stretch ran a structured operator audit under XOP- identifiers, with FS- for skip-hygiene, GH- for GitHub-issue repros, and D2L-Bug- for notebook failures. The last and longest-lived system is the OI-/FU- ledger — OPEN_ISSUES.md, OPEN_ISSUES_DETAILS.md, and FIXED.md at the repo root — where every defect got a stable name and a paper trail that the next agent could pick up.
The letters matter less than the discipline behind them: a test suite you don’t trust is worse than none, because it teaches you to ignore red. So flaky tests were only un-quarantined after an explicit A/B run on real hardware (#59), every skip had to name a tracker or a lint failed the build (#36), and a nasty class of cross-test pollution — one test flipping a global flag and silently breaking a hundred downstream (#11, #12) — was hunted down and killed.
It started with both engines at once
A correction to the obvious story: the port did not begin on the CPU and bolt GPUs on later. The very first commit is the Blackwell port — “Port MXNet to CUDA 13 / cuDNN 9 / sm_120” — and it landed in the same PR (#1) as the oneDNN v3 rewrite of the CPU backend. PR #1 was, in effect, “make it build on Blackwell and modernize the math library,” both at once. Everything later in CUDA-land (#7, #15, #42, #45, #49, #54) was hardening on top of that seed, not the starting point.
oneDNN v3 and the “gate the fast path” pattern
The CPU backend was ported to oneDNN v3, Intel’s modern primitives library — PR #1 alone touched ~95 files. Out of that port came a pattern that recurred for the rest of the project: oneDNN’s fused, optimized kernels make assumptions about their inputs, and when those assumptions don’t hold, the right move is to fall back to the plain operator instead of feeding the fast path bad data.
- Concat/stack input-count gate (#23). oneDNN v3.11’s concat primitive miscounts its own sources near an internal argument-ID boundary; past ~512 inputs a whole cluster of RNN data loaders crashed. Capped the fused path at 256 inputs and fell back above that.
- AVX2 int8 conv+relu gate (#18 → #24). Quantized 1×1 convolutions with fewer than 8 input channels plus a relu post-op produced zeroed output channels. The first guard sat at a layer where shapes aren’t known yet; the fix moved it to where the memory descriptors are actually resolved.
- dnnl FC use-after-free (#60). A channelwise-quantized fully-connected path bound function-local scale objects into a deferred reorder — by the time it ran, the scales were already destroyed. Fixed by submitting immediately when scales are present.
- Fork-safe oneDNN (#18). oneDNN’s internal thread state does not survive
fork(), and every PythonDataLoaderwith workers forks. A post-fork reset handler keeps child processes from inheriting a poisoned state.
The operator-contract audit
The least visible and most systematic correctness work was an audit of the operator output contract. Every MXNet operator is handed an OpReqType telling it whether to overwrite its output (kWriteTo), write in place (kWriteInplace), or add to it (kAddTo). That last one is not a nicety — it is how gradients accumulate. An operator that ignores it and overwrites instead will silently corrupt the backward pass, and you will spend a week blaming your learning rate.
A sweep under the XOP- identifiers went operator by operator making each one honor its request: oneDNN softmax, reductions, quantized batch-dot and batch-norm, embedding, self-attention, and a long tail of contrib ops (most of it in PR #29 and the 2026-05-22/23 commit cluster). It shipped with a reusable contract harness — eventually 12 operators × 36 checks — so the property is tested, not just patched. The same pass hardened the neighborhood: user-facing assert()s became real exceptions, engine and KVStore invariants were promoted to CHECK, and shape-derived integer counters were guarded against silent truncation on large tensors. None of this shows up in a demo. All of it shows up the first time someone trains a model and the loss curve looks subtly wrong.
Blackwell
Making MXNet correct on Blackwell — not just compiling — touched every layer.
- Architecture and toolchain. The CUDA wheel compiles for
sm_80/86(Ampere),sm_89(Ada),sm_90(Hopper),sm_100(datacenter Blackwell), andsm_120(consumer Blackwell), pluscompute_120PTX for forward compatibility. A subtle trap:compute_120PTX does not JIT down tosm_100, so datacenter Blackwell had to be named explicitly (it was missing from an early wheel, #15). cuDNN moved to 9.x and the GEMM paths were modernized onto cuBLASLt. - Version landmines. cuBLAS had to be pinned to a narrow range: one release returned
NOT_INITIALIZEDon large GEMMs on the R580 driver (#42), and another crashed insyrk(#49). Reviving software on new silicon means a real fraction of the work is finding the one dependency version that is broken in neither the old way nor the new. - CUDA Graphs, revived (#45, #54, #70). Graphs capture a sequence of GPU ops once and replay them cheaply, but they were effectively dead here: the core GEMM operators used a legacy cuBLAS path that does capture-illegal host-side setup, fragmenting every network into un-capturable pieces. The fix routed
FullyConnected,batch_dot, andmatmulthrough a capture-safe cuBLASLt path, then handled the genuinely hard part — random numbers under replay, so dropout draws a fresh, correct sequence on each replay instead of freezing one. Graphs are on by default now for hybridized static-shape nets. Measured ~1.5× on a Transformer-like model and ~2.3× on an unrolled LSTM. - Engine correctness under async execution. Two bugs here produced wrong answers rather than crashes — the worst kind. A pool of reusable CUDA events had a guard meant to stop a slot being recycled while still in use, but it never fired, so under load a consumer could synchronize against the wrong stream and read stale data (#46). And nineteen call sites threw away the error code from async memset/memcpy, so a failed launch went silent and the blame landed on a later, innocent kernel (#47). Both fixed, both tested.
- GPU numerics. Reductions like
mean/var/stdover fp16 with a long axis overflowed fp16’s ~65504 range, because the running sum accumulated in fp16 before dividing; the fix accumulates in fp32 and casts down (#45, #47). bf16 conversion was switched from truncation to round-to-nearest-even to match PyTorch (#45).
Apple Silicon
Getting MXNet to build on an arm64 Mac was step one; getting it to compute correctly was step two, and step two had the interesting bugs.
- Bring-up (#26, #27). AppleClang rejected dependent-name template syntax that GCC had quietly tolerated. BLAS was routed through Apple’s Accelerate framework (ships on every Mac, native arm64), the x86-only SSE/F16C intrinsics were gated off, and the async teardown paths were hardened.
- OpenMP from scratch (#61). macOS ships no OpenMP runtime, so oneDNN was running single-threaded. The fix is hermetic: the build fetches and compiles the LLVM OpenMP runtime (llvmorg-22.1.5) for arm64 into a local
.deps/prefix and links it automatically, turning oneDNN multi-core on the Mac. - Native fallbacks (#28). oneDNN v3 routes several primitives through a JIT (Xbyak_aarch64) that fails on Apple Silicon. One guard wired into ~25 operator support-checks falls each back to the stable native CPU path.
- Bugs that only appear on arm64. Because macOS multiprocessing defaults to
spawn(notfork), and because everything heavy runs the native path on arm64, several latent bugs surfaced only here: a shared-memory segment unlinked too early, so spawned data-loader workers couldn’t re-attach (#50, which tooktest_gluon_data.pyfrom 7 failures to 44 passing); a bf16 activation/pooling path that aborted with “Unknown type enum 12” (#50); and the max-pool / convolution NaNs from the last post (#79). Running the full 10,525 ONNX export tests on the Mac surfaced an RNN-backward gradient-accumulation bug for free (#39).
Numerics that match NumPy and PyTorch
Legacy code only gives the right answer if the operators behave the way its author expected. A pass aligned the numpy-operator semantics with NumPy/PyTorch: integer matmul/dot now promote-compute-cast instead of being rejected (#67); 0-d array indexing accepts ..., newaxis, and full slices like NumPy (#48 — found because NumPy’s own nanstd does a[:] = v internally); and integral-valued float indices are coerced rather than rejected (#51), which matters because MXNet’s default dtype is float32, so mx.np.array([0,1,2]) is float, and the strictly-correct “indices must be integers” check broke an idiom used all over D2L.
Wheels that just install
The packaging follows PyTorch’s model: declare the big CUDA libraries as pip dependencies rather than bundling them (the first attempt shipped a 2.22 GB wheel that blew past GitHub’s asset limit, #5), but do bundle OpenCV, oneDNN, and — on macOS — a hermetic OpenMP, so import mxnet works on a clean machine with no system OpenCV. One shared script (build_cleanup_wheel.sh) auto-detects the flavor (CUDA / Linux-CPU / macOS, all cp312) and runs configure → build → bundle the native closure → patch library paths ($ORIGIN RPATHs via patchelf on Linux; @loader_path rewrites plus re-signing via install_name_tool/codesign on macOS) → provenance gate.
That gate (release_provenance.py) refuses to package unless the git tree is clean, the feature flags match what was requested, and the full native closure is actually bundled. It exists because of a specific recurring bug: a transitive OpenCV codec dependency (libcharls on Linux, libsharpyuv on macOS) left unbundled, which imports fine on the build host — where the system has those libraries — and fails only on a clean machine. The defense is a clean-room import test: install the wheel into a stripped container with nothing but libgomp1 and check that it still imports (#62, #63, #87).
The wheels themselves live at smolix/mxnet, including a pared down automatic documentation, and the three builds are attached to the mxnet-2.0.0.zombie.1 release: CUDA 13 / Blackwell, x86-64 Linux CPU, and Apple Silicon CPU, all cp312, each tagged with the matching …zombie.1 version so you can see at a glance which one you’ve got.
CI cheap enough to run nightly
A library that takes ~70 minutes to compile makes naive CI both slow and expensive, so the pipeline is built around compile-once, test-many: one job builds libmxnet.so and uploads it as an artifact; the test job, the docs link-check, and the docs deploy all consume that same artifact instead of rebuilding (#17). Every PR runs a tight <20-minute subset; the exhaustive sweep runs nightly, each target in its own process to dodge the OOM-kill a single giant process used to hit (#68). A 5-second gate job skips the whole nightly when HEAD is unchanged since the last green run (#94). The OpenCV install was narrowed from the hundreds-of-megabytes libopencv-dev metapackage to exactly the three libraries libmxnet.so actually links, with retries and timeouts so a slow mirror fails fast rather than hanging for half an hour (#96). And the cold-build “death spiral” — where a first run on a new branch timed out before it could save its compiler cache, so the next run also started cold — was broken by right-sizing the runner assumptions and raising the timeout above the real cold-build time, so the cache finally seeds (#52, #53).
Where it lands
Three wheels, one pip install, correct numerics on Blackwell, x86 Linux, and Apple Silicon — and a test suite that grew one regression test per grave dug. Docs and wheels are all on smolix/mxnet (the mxnet-2.0.0.zombie.1 release); the standing warning still applies — use at your own risk.
The throughline is the unglamorous one I keep coming back to: on a numerical library the tests are the spec, and porting to new silicon is the long, patient work of finding every place where the old code stopped being correct without ever stopping to compile — and writing down the test that proves you fixed it. The zombie walks. It just needs supervision.