Next week I am teaching a tutorial on efficient LLM inference at the Machine Learning Summer School 2026 in NYC, hosted this year at Columbia University. The slides are below. There are about 150 of them, which sounds small, given how far the field has come.
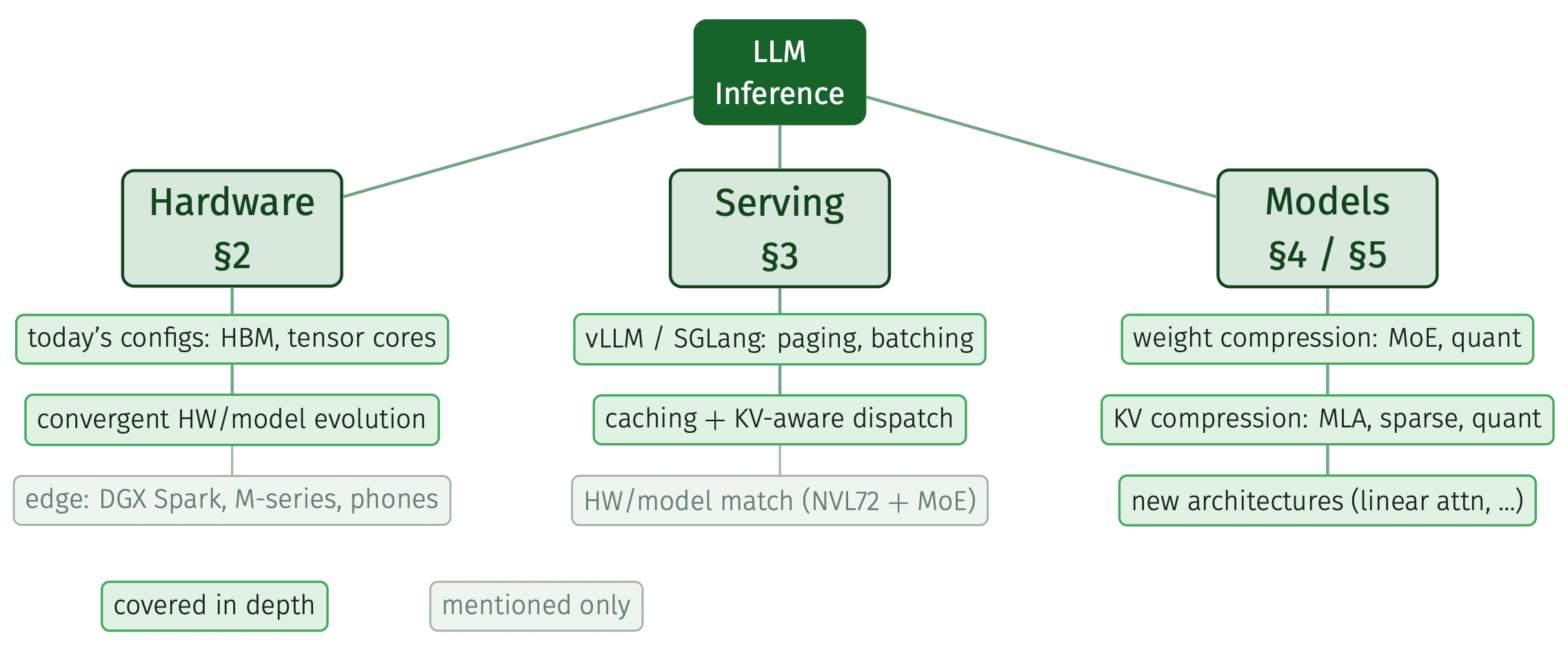
It’s a good opportunity to review how we have this exciting convergent evolution of models, hardware, and algorithms for serving efficiency. Be prepared for a deep dive into chips, bandwidth but also randomized algorithms and architectures. My goal was to write a practitioner’s guide in six parts. The running example throughout is Qwen3, both the dense 8B and the 30B-A3B mixture of experts, at a 40k token context.
- Overview. Prefill versus decode, arithmetic intensity, and the roofline plot that tells you which of the two you are fighting.
- Hardware. The physics of the box: bandwidth ladders, the FP8 and FP4 number formats, why a single DRAM access costs about 500 multiplies, and why compute grows roughly 4x per hardware generation while memory bandwidth only doubles. There is also the at-home angle, where a DGX Spark, a Strix Halo box, or an Apple Silicon Mac with plenty of unified memory turns out to be a surprisingly good decode machine.
- Serving. Continuous batching, PagedAttention, prefix caching, RadixAttention, and splitting prefill off from decode onto separate hardware. Fun fact: your API bill is probably a cache-hit-rate report. Tools: vLLM and SGLang.
- Weight compression. Mixture of experts as “do not touch most of the weights,” then quantization down to four bits, and the rather pretty fact that the exponents of trained weights are almost losslessly compressible to about 4.7 bits each.
- KV compression. Shrinking the other thing that saturates your memory bus once the context gets long.
- Wrap-up and resources. Where to actually get all of this, and the papers behind each trick.
It is teaching first, so diagrams beat equations and equations beat walls of text, with source references to lots of papers. All number verified in June 2026 (and probably wrong by December).
Slides: Efficiency in LLMs (PDF, 47 MB) · Machine Learning Summer School 2026, Columbia.