
The natural reaction to the Pokémon theorem is to escape into representation learning. If finite scalar checklists cannot catch every fairness violation, then bake fairness into the features once. Ship a single encoder \(\Phi : \mathcal{X} \to \mathcal{Z}\) and let every downstream predictor inherit fairness for free. There is a real and serious literature behind exactly this idea: Zemel et al. (2013), Edwards and Storkey (2016), Louizos et al. (2016), Madras et al. (2018). It is a beautiful agenda, and it has a serious flaw…
What “fair features” actually demand
Two desiderata for a feature map \(\Phi\):
- Predictive signal. \(\Phi(X)\) carries information about \(Y\) (otherwise we can’t use it for classification).
- Distributional insensitivity to the group attribute \(G\). That is, the group attribute shouldn’t matter in aggregate for the feature distribution. Operationally this gets split into two pieces:
- Parity in the representation: \(\mu_{\Phi,a} = \mu_{\Phi,b}\).
- Class-conditional separation: \(\mu_{\Phi,y,a} = \mu_{\Phi,y,b}\) for each \(y \in \{0, 1\}\).
Without the second piece the goal collapses into a triviality: throw away all signal about \(Y\) and parity is automatic. Both together is the operational definition of a fair feature, and it is the form every paper above is chasing. The notation is the same as in the previous post: \(\mu_{\Phi,g} := \mathbb{E}[\phi_\mathcal{Z}(\Phi(X)) \mid G = g]\) is the conditional mean embedding of the representation, and \(\mu_{\Phi,y,g} := \mathbb{E}[\phi_\mathcal{Z}(\Phi(X)) \mid Y = y, G = g]\) adds the class.
Linear algebra strikes again
Apply the law of total expectation conditional on \(G = g\). With class-conditional separation, the class-conditional means \(\mu_{\Phi,y,g}\) do not depend on \(g\), so we can drop the subscript and write \(\mu_{\Phi,y}\). Then we can write the per-group mean as
\[\mu_{\Phi,g} \;=\; p_g \, \mu_{\Phi,1} + (1 - p_g)\, \mu_{\Phi,0}.\]
Here \(p_g = \Pr(Y = 1 \mid G = g)\) is the group-specific base rate. Subtract across groups:
\[\mu_{\Phi,a} - \mu_{\Phi,b} \;=\; (p_a - p_b)\,(\mu_{\Phi,1} - \mu_{\Phi,0}).\]
Parity zeros the left-hand side. Unequal base rates \(p_a \neq p_b\) zero the scalar coefficient. The bracket must vanish:
\[\mu_{\Phi,1} \;=\; \mu_{\Phi,0}.\]
In other words, the distributions for positive and negative classes match, since under a characteristic kernel on \(\mathcal{Z}\), equality of mean embeddings lifts to equality of distributions. We get \(\Phi(X) \perp Y\). No measurable downstream predictor on \(\Phi(X)\) retains any signal about \(Y\).
The representation has been flattened. Both stacks of pancakes are now one.
Why this is harder to swallow than the Pokémon theorem
The Pokémon theorem said some fairness criterion remains unaudited after any finite checklist. There was a residual, and you could go bigger. The collapse here is not a residual. It is the joint distribution of \((\Phi(X), Y)\) being degenerate. Whatever your encoder is (linear, kernel, deep network, contrastive, adversarial), if it satisfies parity and class-conditional separation exactly and base rates differ, there is nothing in there about \(Y\). Closely related observations appear in Lechner et al. (2021) and Zhao and Gordon (2022); the conjunction form here pins down the exact obstruction.
There is a decade of work that took the two desiderata as a starting point and built encoders that approximately satisfied both. The theorem does not say those encoders are useless. It only says that the limit they were chasing is empty (but there’s hope — see the next section).
The escape
The exact collapse only bites when both constraints hold exactly. Relax to \(\varepsilon\)-parity and \(\rho\)-class-separation and you get that the usable class-conditional signal is bounded by
\[\frac{\varepsilon + \rho}{|p_a - p_b|}.\]
Linear in the joint fairness budget, rescaled by the base-rate gap. As \((\varepsilon, \rho) \to (0, 0)\) the bound collapses to zero, matching the exact theorem. But for any positive budget there is a real Pareto frontier you can navigate and trade off fairness for usefulness in features.
The practical lesson is that the question is not whether your representation is fair. It is which fairness budget you spent and how much class signal you have left. Spend it deliberately.
The forbidden corner
The experimental check across three standard fairness benchmarks:
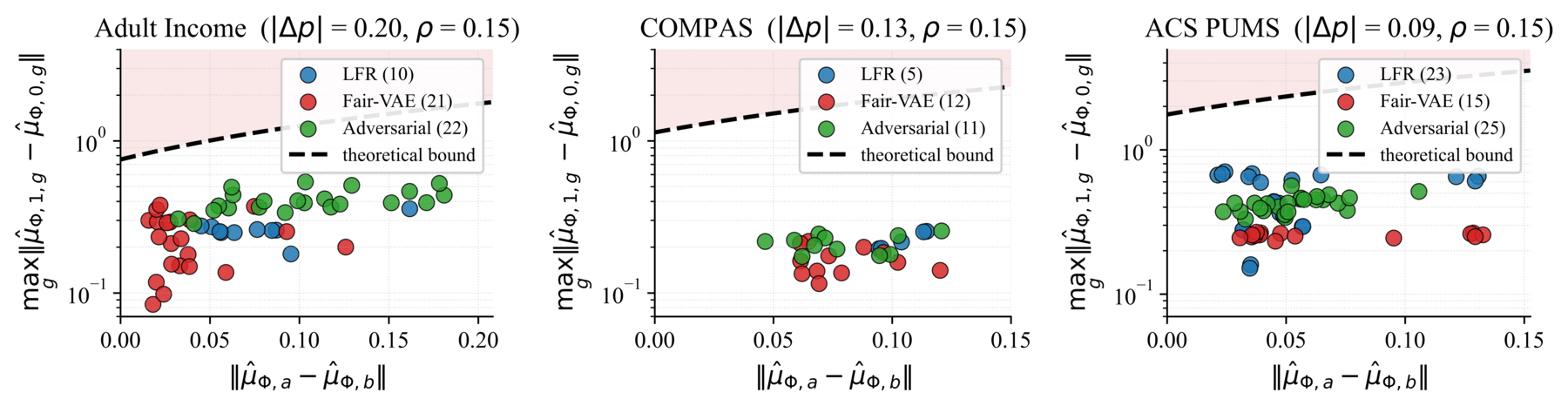
Each panel plots the parity gap \(\|\hat\mu_{\Phi,a} - \hat\mu_{\Phi,b}\|\) on the horizontal axis against the largest class-conditional gap \(\max_g \|\hat\mu_{\Phi,1,g} - \hat\mu_{\Phi,0,g}\|\) on the vertical axis. The line \(y = (x + \rho) / |\Delta p|\), with \(\Delta p = p_a - p_b\), is the theoretical bound from the approximate version of the theorem (Theorem 6.1 in the paper). The upper-left corner (small parity gap, large class-conditional signal) is the forbidden region.
The forbidden region is empirically empty. LFR, Fair-VAE, and adversarial debiasing across all three datasets cluster on the allowed side of the line. They are doing the only thing they can.
Closing
The Pokémon theorem said finite scalar checklists cannot catch every violation. The pancake theorem says perfect fair representations cannot retain \(Y\). Two different orthogonality arguments, same RKHS engine. The paper has a Pokémon–KMR bridge and minimax rates for the approximate versions of both.
Paper: arXiv:2605.09221. Joint with Daniel Matsui Smola.